Cloudflare acusa a Perplexity de evadir bloqueos con rastreadores encubiertos
Cloudflare acusa a Perplexity de evadir bloqueos con rastreadores encubiertos
El motor de búsqueda basado en inteligencia artificial Perplexity ha sido acusado por Cloudflare de utilizar “tácticas encubiertas” para ignorar directivas explícitas que impiden el rastreo de sitios web. Según un informe publicado por la compañía el lunes 4 de agosto de 2025, Perplexity habría eludido los bloqueos establecidos por archivos robots.txt y reglas de firewalls, empleando bots no identificados oficialmente y direcciones IP rotativas para continuar accediendo a contenido protegido.
Cloudflare —proveedor líder de servicios de seguridad, CDN y optimización web— explicó que recibió múltiples reportes de clientes cuyos sitios estaban configurados para bloquear los bots de Perplexity, tanto mediante robots.txt como a través de firewalls de aplicaciones web. A pesar de ello, el contenido seguía siendo accedido, lo que motivó una investigación directa por parte de los ingenieros de la empresa.
La investigación reveló que, al detectar restricciones, los rastreadores oficiales de Perplexity eran sustituidos por un “crawler no declarado”, el cual operaba desde IPs fuera del rango publicado por la compañía. Estas IPs, además, eran rotadas con frecuencia y distribuídas entre diferentes Sistemas Autónomos (ASN), dificultando su detección y bloqueo. Cloudflare indicó que este comportamiento fue observado en más de 10,000 dominios y en millones de solicitudes diarias.
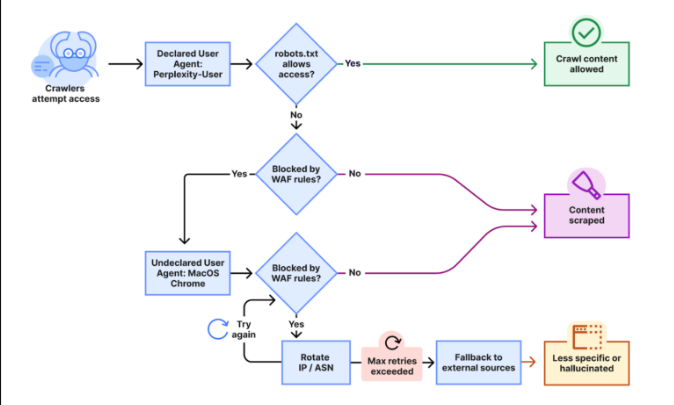
Este tipo de práctica representa una violación directa al Robots Exclusion Protocol, un estándar propuesto en 1994 por el ingeniero Martijn Koster y formalizado por la Internet Engineering Task Force (IETF) en 2022. El protocolo establece una forma simple y clara de comunicar a los rastreadores qué partes de un sitio están fuera de los límites, mediante el uso de un archivo robots.txt ubicado en la raíz del dominio.
Perplexity no es la única empresa de IA señalada por ignorar estas normas. El CEO de Reddit, Steve Huffman, ya había criticado en 2024 el comportamiento de Perplexity, Microsoft y Anthropic, acusándolos de actuar como si “todo el contenido de Internet fuera de libre uso”. Huffman calificó la situación como “un verdadero dolor de cabeza” y denunció la actitud permisiva de estas empresas respecto a los límites impuestos por los propietarios de contenido.
En meses recientes, medios como Forbes y Wired también han acusado a Perplexity de plagiar artículos y de manipular los identificadores de sus bots para evadir controles. Forbes describió el acto como un “robo cínico” luego de que Perplexity publicara contenido casi idéntico a uno de sus artículos propietarios, apenas un día después de su publicación original.
En respuesta a los hallazgos, Cloudflare ha tomado medidas concretas: eliminó a Perplexity de su lista de bots verificados y añadió heurísticas a sus reglas de seguridad para bloquear las actividades de rastreo encubierto. En su comunicado, los investigadores de la compañía subrayaron que los rastreadores deben ser transparentes, tener un propósito claro, realizar actividades específicas y, sobre todo, respetar las preferencias y directivas de los sitios web.
Hasta el momento de publicación, Perplexity no ha respondido a las solicitudes de comentarios sobre las acusaciones. Mientras tanto, el caso pone de nuevo en tela de juicio las prácticas de los actores más influyentes en el creciente ecosistema de herramientas de inteligencia artificial y su relación con los derechos de acceso y control de la información en la web.